Web Scraping EBAY with ScrapeOps & Rust
In this article I show some code to web scrape EBAY using Rust and a proxy provided by ScrapeOps


The code below uses the ScrapeOps endpoint : “https://proxy.scrapeops.io/v1/” and the requests are forwarded on to your chosen url to scrape.
How to get an API key?
You can get a free one, with 1000 tokens as a trial :
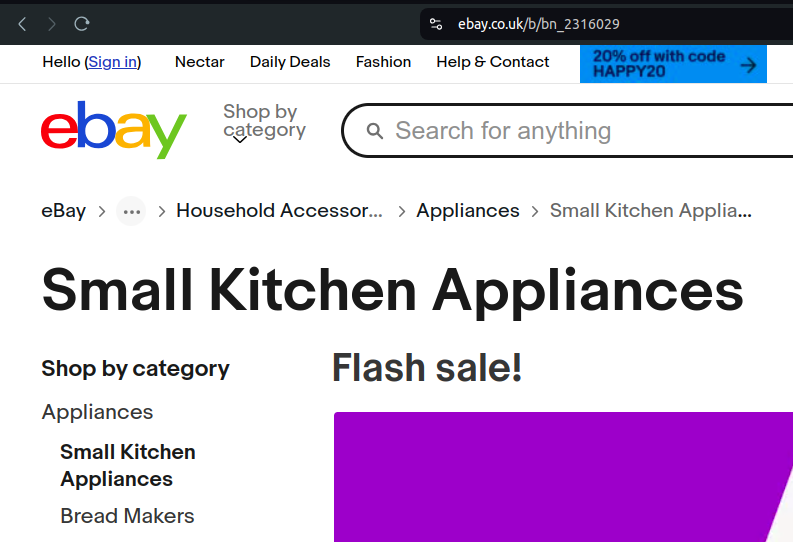
Category to Scrape
I chose this, but you can chose a different one, and just alter the number on the end of the url in the code below.
You use your browser developer tools, inspect the html and once you’ve expanded it, locate the part you need.
Just right click on the text, then use “Copy” > “Copy outer HTML” – and although CSS is the usual way. (You can also use the XPath).
In this instance we use “s-item_title” which gives us the item title – we use it on line 28 in our code, see below
[dependencies]
reqwest = { version = "0.12.7", features = ["blocking"] }
scraper = "0.20.0"use reqwest::blocking::Client;
use scraper::{Html, Selector};
use std::error::Error;
use std::fs::OpenOptions;
use std::io::Write;
use std::time::Duration;
use std::env;
fn generate_url(base_url: &str, page_number: u32) -> String {
format!("{}?_pgn={}", base_url, page_number)
}
fn scrape_and_extract_titles(url: &str, api_key: &str, file: &mut std::fs::File) -> Result<bool, Box<dyn Error>> {
let client = Client::builder()
.timeout(Duration::from_secs(120))
.build()?;
let response = client.get("https://proxy.scrapeops.io/v1/")
.query(&[("api_key", api_key), ("url", url), ("render_js", "true")])
.send()?;
if response.status().is_success() {
println!("---------------------------");
println!("Successfully scraped {}", url);
let body = response.text()?;
let document = Html::parse_document(&body);
let selector = Selector::parse("h3.s-item__title").unwrap();
let titles: Vec<_> = document.select(&selector).collect();
if titles.is_empty() {
println!("No more titles found, stopping.");
return Ok(false);
}
for title in titles {
let title_text = title.text().collect::<Vec<_>>().join(" ");
println!("{}", title_text);
writeln!(file, "{}", title_text)?;
}
Ok(true)
} else {
println!("Failed to scrape {}: {}", url, response.status());
Ok(false)
}
}
fn main() -> Result<(), Box<dyn Error>> {
let api_key = env::var("SCRAPOPS_API_KEY").unwrap_or("default_value".to_string());
let base_url = "https://www.ebay.co.uk/b/bn_2316029";
let mut page_number = 1;
let mut file = OpenOptions::new()
.append(true)
.create(true)
.open("scraped_titles.txt")?;
loop {
let url = generate_url(base_url, page_number);
if !scrape_and_extract_titles(&url, &api_key, &mut file)? {
break;
}
page_number += 1;
}
Ok(())
}