RAG with Qdrant and Rust 🦀(&FastEmbed)
2025 was when MCP and RAG made some headlines in the ‘AI’ world, but despite the hype and the counter-hype, we just got on with building.
This design performs RAG with Qdrant and Rust.
This article shows and gives an overview of a highly usable, and useful solution

semantic similarity search
Find highly relevant results even when specific keywords are not matching, using the data that you collected / created
Why RAG ?
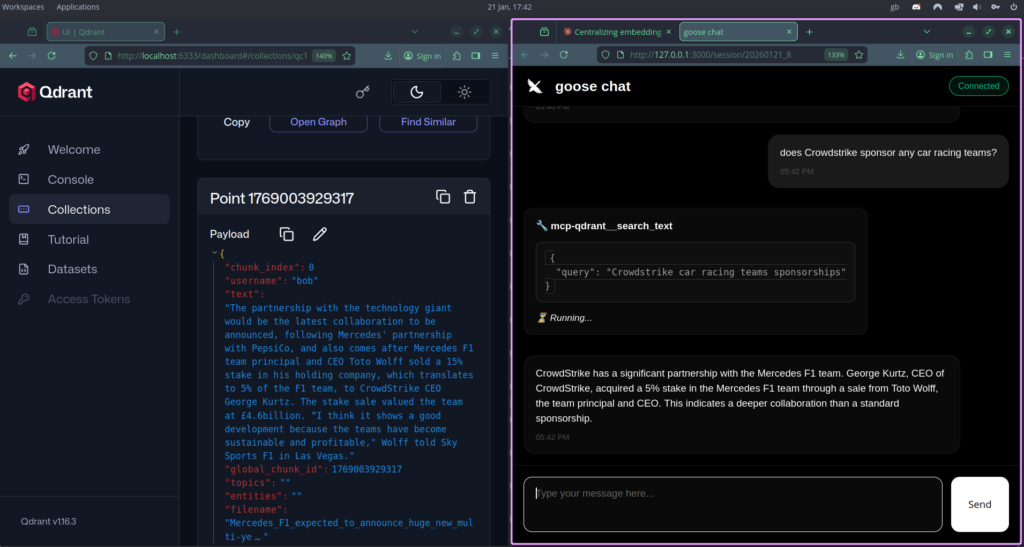
RAG allows you to populate your own database (Qdrant Vector database) with your own data (scraped, downloaded, created by you).
You ask the LLM a question, it uses the MCP server to query your data and gives you back an answer based on high scoring results to your query.
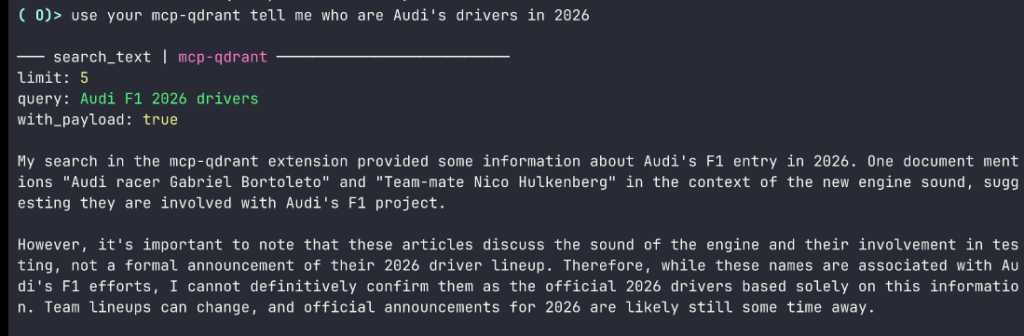
If you wanted to ask an LLM about the 2026 F1 season in January of 2026 it would be ignorant.
It would not have recent knowledge after its training cut off date.
With recent data that you have gathered and “upserted” to Qdrant, the LLM can use its MCP to access your local, current/recent data
Without RAG ~ Qdrant MCP

With RAG ~ Qdrant MCP
Animation:

Why do RAG with Qdrant and Rust?
If you have tried Qdrant Vector Database you will be familiar with it’s client library, which is very ergonomic.
You may have considered a ‘RAG’ project for your business, project, study, but found the cost of tokens a bit too off-putting?
Enter “FastEmbed”
FastEmbed is a ‘crate’ (A crate is Rust’s version of a Python Module).
FastEmbed makes it possible to do the embeddings with local embedding models.
Writing code in Rust means many of the errors that occur at runtime in Python are eradicated before compiling to a Rust binary executable.
Solution
With the right design decisions and architecture the code is robust, accurate and overcomes the issues raised in 2025 by many critics of RAG
Qdrant is fast*, Rust is fast, they are both robust, and the MCP server with tools to query Qdrant is also built in Rust.
This Rust implementation sidesteps all of the usual criticisms.
FastEmbed runs locally with zero API costs,
No rate limits, no surprise bills, no dependency on external services.
The perfect combo n’est pas?
For more info contact me – I can show you a full demo or advise on your project.
I can also show “how to get your data into Qdrant” without the assistance of a red squirrel.
*Qdrant delivers lightning-fast vector search with millisecond response times, and the entire stack can be self-hosted.


