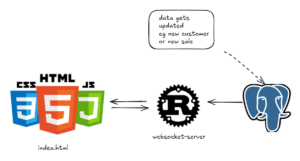
Web Scraping EBAY with ScrapeOps & Python
Web Scraping requires specific tools and techniques, let’s look at our favourite one, ScrapeOps :

“ScrapeOps provides a suite of web scraping tools that makes it easier to deploy, scheduling and monitor your web scrapers and data extraction feeds in production.”


The need for data is relentless – more and more AI projects rely on specific data and it is become increasingly harder to extract
Introduction
We’ll make a few basic assumptions.
- You’re using Python
- The site you want to scrape returns errors when you use “requests”and the usual headers and params
- Basic familiarity with Beautiful Soup and CSS exractors

Web Scraping with ‘ScrapeOps Python Request SDK’
Once you start scraping multiple pages or crawling one large site you’ll want to track your progress and have a central way to monitor the progress of your spiders.
ScrapeOps makes this particularly straightforward:
Get started with code: Python & ScrapeOps
You can register for access to their API for free, with 1000 tokens, however, you’ll need to subscribe thereafter.
Let’s start our journey using “requests” and Python.
Code Explanation: Scraping eBay Titles with ScrapeOps
We’re going to scrape the title text of every item in Ebay “Small Kitchen Appliances” and then save to a text file.
For the official ScrapeOps Ebay guide check this article 👀
I chose this category as it will yield over 2000 results and demonstrate the robustness of a scraper that uses ScrapeOps – if you keep waiting for a 500 error you won’t get one!
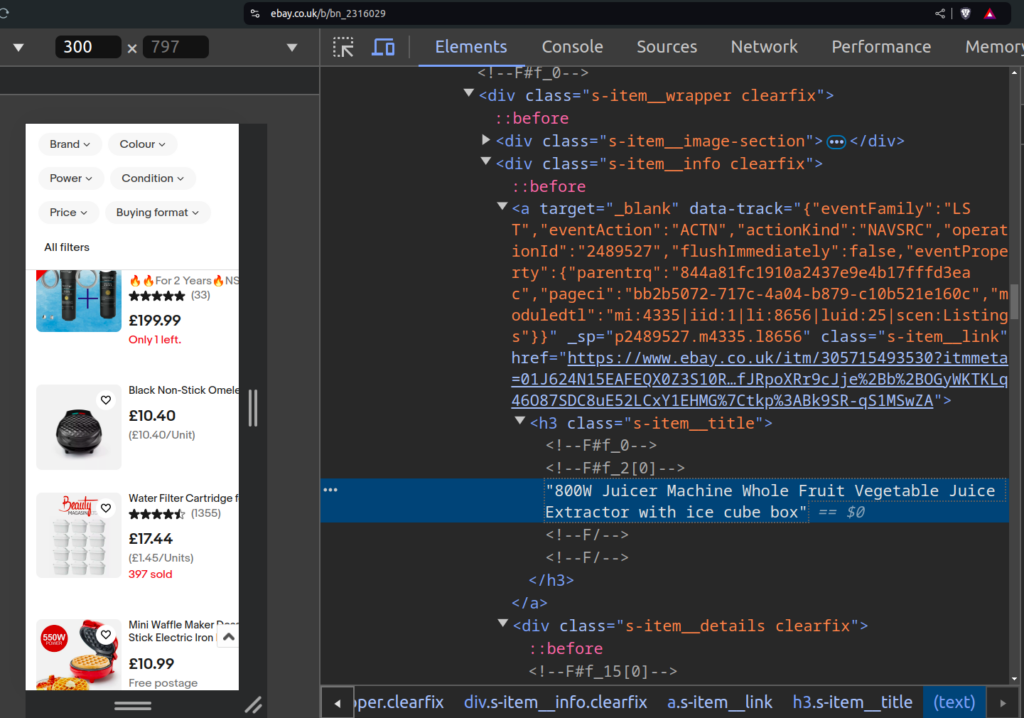
How do you get the extractor?
You use your browser developer tools, and then inspect the html and once you’ve expanded it and located the part you need.
Just right click on the text, then use “Copy” > “Copy outer HTML” – and although CSS is the usual way. (You can also use the XPath).
In this instance we use “s-item_title” which gives us the item title – we use it on line 33 in our code, see below
Full Python code
This code is designed to scrape product titles from eBay using the ScrapeOps Python Requests Wrapper, a tool that simplifies web scraping by managing proxies, logging, and more. Below is a breakdown of how the code works:
pip install scrapeops-python-requests
pip install beautifulsoup4import requests.exceptions
from bs4 import BeautifulSoup
from scrapeops_python_requests.scrapeops_requests import ScrapeOpsRequests
# API Key for ScrapeOps (hidden for security)
API_KEY = "############"
# Initialize the ScrapeOps Logger
scrapeops_logger = ScrapeOpsRequests(
scrapeops_api_key=API_KEY,
spider_name='EbayScraper',
job_name='EbayTitleJob',
)
# Initialize the ScrapeOps Python Requests Wrapper
requests = scrapeops_logger.RequestsWrapper()
def generate_url(base_url, page_number):
return f"{base_url}?_pgn={page_number}"
def scrape_and_extract_titles(url, api_key, file):
try:
response = requests.get(
'https://proxy.scrapeops.io/v1/',
params={'api_key': api_key, 'url': url, 'render_js': True},
timeout=120
)
if response.status_code == 200:
print("---------------------------")
print(f'Successfully scraped {url}')
soup = BeautifulSoup(response.content, 'html.parser')
titles = soup.find_all('h3', class_='s-item__title')
if not titles:
print("No more titles found, stopping.")
return False
for title in titles:
title_text = title.get_text(strip=True)
print(title_text)
file.write(title_text + '\n')
scrapeops_logger.item_scraped(
response=response,
item={'title': title_text}
)
return True
else:
print(f'Failed to scrape {url}: {response.status_code}')
return False
except requests.exceptions.RequestException as e:
print(f'Error scraping {url}: {e}')
return False
base_url = "https://www.ebay.co.uk/b/bn_2316029"
page_number = 1
with open('scraped_titles.txt', 'a') as file:
while True:
url = generate_url(base_url, page_number)
if not scrape_and_extract_titles(url, API_KEY, file):
break
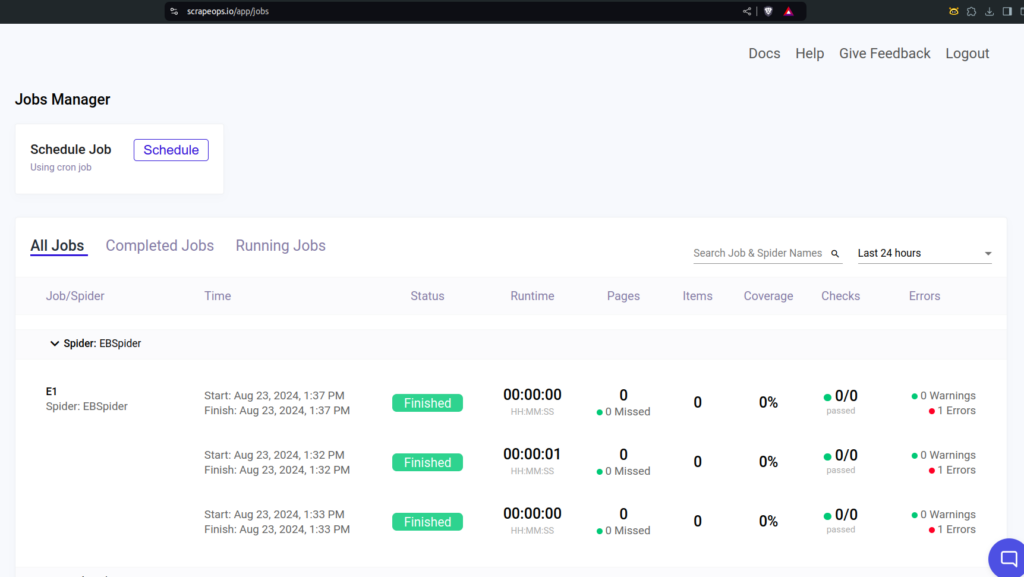
page_number += 1ScrapeOps in action:
The ScrapeOps dashboard shows the success or occasionally an error, which is nicer to view instead of just viewing the stats in your terminal.

Key Components:
- Imports:
requests.exceptions: Handles exceptions that may occur during the HTTP request process.BeautifulSoup: A part of the BeautifulSoup library used for parsing HTML content.ScrapeOpsRequests: A class from the ScrapeOps library that helps with web scraping, proxy management, and logging. Make sure you have added it with pip install before running your code.
- API Key:
- The
API_KEYis used to authenticate requests through ScrapeOps. For security reasons, this key has been hidden. You would most likely want to store in a .env file especially if you were committing to GitHub! - If running locally, or for production, use a dedicated secrets management service. Eg. AWS Secrets Manager, HashiCorp Vault, or Azure Key Vault. These services securely store and manage API keys, providing access control and auditing features.
- ScrapeOps Logger Initialization:
scrapeops_loggeris initialized to handle logging and tracking for the scraping job namedEbayTitleJobassociated with the spiderEbayScraper– it’s not essential for the code to work, but very useful.
- Requests Wrapper Initialization:
- The
requestsobject is a wrapped version of therequestslibrary provided by ScrapeOps to manage requests with additional functionality like proxy rotation.
- Generating URLs:
generate_url(base_url, page_number)constructs the full URL for a specific page on eBay by appending the page number to the base URL.
- Scraping and Extracting Titles:
scrape_and_extract_titles(url, api_key, file)sends a GET request to the eBay URL through ScrapeOps’ proxy service, parses the HTML content to find product titles, and writes them to a file. If scraping fails, it logs the error and stops further processing.
- Main Scraping Loop:
- The main loop iterates over eBay pages, calling
scrape_and_extract_titlesfor each page until no more titles are found or an error occurs. Titles are saved toscraped_titles.txt.
Conclusion – Web Scraping
Thanks for reading this far!
Finally, to wrap up : this code provides a solid foundation for scraping eBay titles using ScrapeOps, with robust error handling and logging for monitoring the scraping process.
The use of ScrapeOps ensures that the web scraping is managed effectively, reducing the risk of being blocked by the target site. You’ll find the “js” feature particularly useful as well. It saves you having to attempt to render it locally, especially when scraping something like a sports betting site or similar.
Useful links :