Compare pre-trained Sentence Transformer models
To begin with, when learning about ML/AI you may just use the model specified in the tutorial you’re doing, but later on you’ll want to research, test, and evaluate different models based on size, performance and write your code to suit.

Let's compare output using 2 different models that I used in a recent project for semantic search :
https://qdrant.tech/documentation/overview/vector-search
According to the documentation for SBERT - "The all-mpnet-base-v2 model provides the best quality, while all-MiniLM-L6-v2 is 5 times faster and still offers good quality."
Here are the results from the same code, but using different models to embed and query Rightmove Property listings
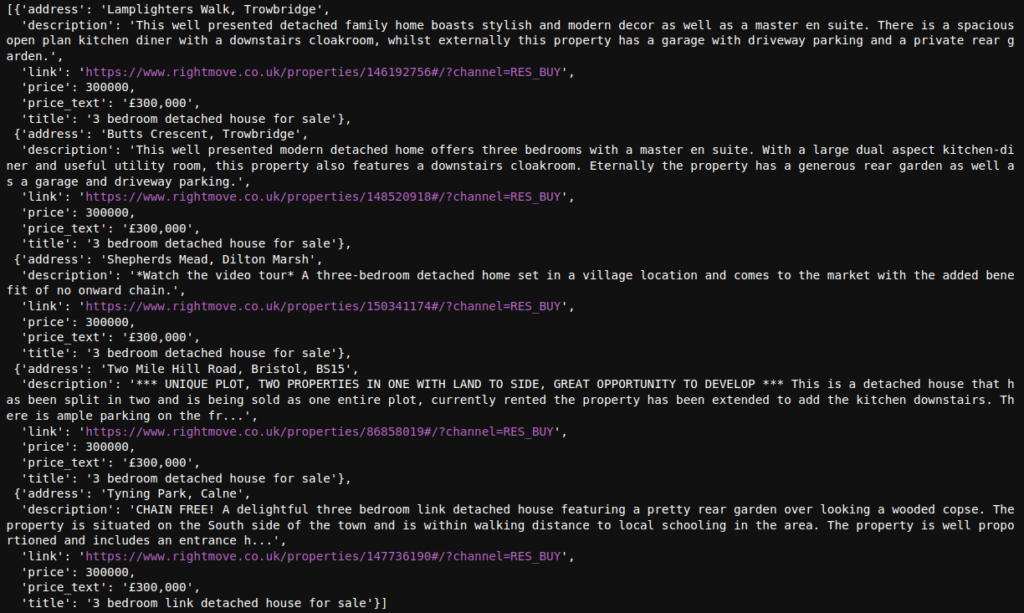
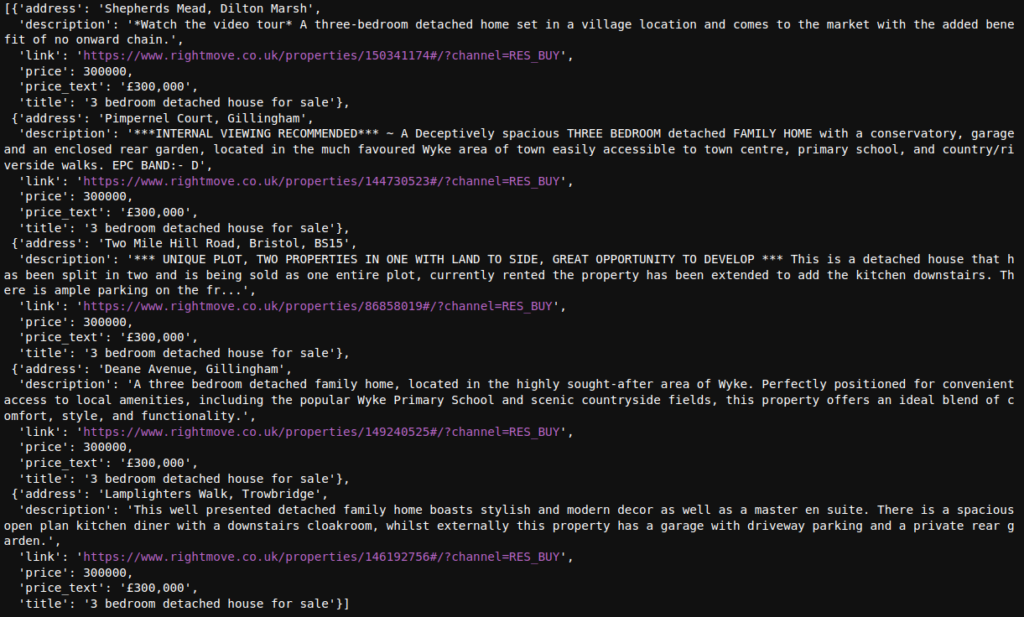
“Intended to be used as a sentence and short paragraph encoder. Given an input text, it outputs a vector which captures the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
By default, input text longer than 256 word pieces is truncated.”
What does the “L” mean?
The sentence-transformers/all-MiniLM-L12-v2 and sentence-transformers/all-MiniLM-L6-v2 are both models from the Sentence Transformers library, specifically designed for tasks like semantic search, clustering, and paraphrase mining. They are built using the MiniLM architecture but differ primarily in their size and, consequently, their performance and efficiency.
Key Differences
- Model Size:
all-MiniLM-L12-v2: This model has 12 layers.all-MiniLM-L6-v2: This model has 6 layers.
- Performance:
- Accuracy and Embedding Quality: Generally, the
L12model (with 12 layers) is expected to provide higher quality embeddings compared to theL6model (with 6 layers). This is because deeper models can capture more complex representations of the input data. - Inference Speed: The
L6model, having fewer layers, will be faster in inference compared to theL12model. This can be particularly beneficial when dealing with real-time applications or limited computational resources.
- Memory and Computational Requirements:
- The
L12model will require more memory and computational power both for training and inference due to its increased number of parameters. - The
L6model is more lightweight, making it more suitable for deployment in environments with constrained resources.
Use Cases and Recommendations
- all-MiniLM-L12-v2:
- When to Use: Choose this model when you need higher accuracy and the best possible quality of sentence embeddings. It is suitable for applications where the slight increase in computational cost is acceptable for the benefit of better performance.
- Typical Applications: Semantic search engines, high-quality text clustering, paraphrase detection, and other tasks where the quality of embeddings is crucial.
- all-MiniLM-L6-v2:
- When to Use: Opt for this model if you need faster inference and have limited computational resources, while still requiring reasonably good performance. It strikes a balance between speed and accuracy.
- Typical Applications: Real-time applications, deployment on edge devices, or scenarios where you need to process a large volume of text quickly.
Summary
- L12 (12 layers): Better performance and higher quality embeddings, but slower and more resource-intensive.
- L6 (6 layers): Faster and more efficient, with a slight trade-off in embedding quality.
Your choice between the two should depend on your specific application requirements and constraints. If computational resources and speed are critical, all-MiniLM-L6-v2 is a good choice. If embedding quality and accuracy are paramount, then all-MiniLM-L12-v2 is preferable.
Verdict
Both work, but give slightly different results. For more info, check this comparison table
Make sure you use the correct dimensions eg 384 or 768 specific to the model you are using!
Else error!
Tip! – You can also use model.get_sentence_embedding_dimension() to get the dimensionality of the model you are using.
See also : https://www.sbert.net/docs/sentence_transformer/pretrained_models.html#semantic-similarity-models
Rightmove Property Semantic Search
A note on Metrics
When configuring vector parameters for tasks like similarity search, clustering, or classification, you need to choose a distance metric that will measure the similarity or dissimilarity between vectors. The choice of distance metric can significantly impact the performance of your model.
Common Distance Metrics
- Cosine Similarity:
- Formula: Cosine similarity measures the cosine of the angle between two vectors.
- Range: The result ranges from -1 to 1, where 1 means the vectors are identical, 0 means they are orthogonal, and -1 means they are diametrically opposite.
- Use Case: Cosine similarity is particularly useful when the magnitude of the vectors is not important, but the orientation is. It is widely used in text analysis and NLP tasks, where vectors represent the direction of the word embeddings rather than their magnitude.

