On premise AI for business
In this article we show how to leverage a Large Language Model and a Vector Database to search private data without touching the internet. Why worry? Well, for instance, 11% of data employees paste into ChatGPT is confidential! On premise AI for business is not as difficult as it may sound…
This article will guide you through the steps and the code to set up a semantic search over your existing PDF text document(s)
Please feel free to contact us if you have an idea or would like to find out more
advertisement

Why on-premise?
https://www.cyberhaven.com/blog/4-2-of-workers-have-pasted-company-data-into-chatgpt
Keeping AI data on-premise rather than using cloud-based large language models (LLMs) can be crucial for maintaining control over sensitive information.
On-premise solutions offer enhanced security by reducing exposure to potential data breaches and unauthorized access, which can be a risk in cloud environments.
Regulatory compliance requirements, such as GDPR in the EU, may necessitate strict data residency and privacy measures that are easier to enforce on-premise.
Furthermore, on-premise AI provides greater customization, performance optimization, and control over the AI infrastructure.
Additionally on-premise AI ensures that data handling aligns closely with the organization’s specific needs and policies.
** You will still need an internet connection to download the relevant tools whilst building the code, after that, it’s all local.
RAG is a way to leverage high-value, proprietary company knowledge that will never be found in public datasets used for LLM training.”
https://qdrant.tech/articles/rag-is-dead
How to use Large Language Models locally
We will develop an on-premise semantic searcher using Python
Download the language model from Hugging Face.
Data is ingested into Qdrant vector database.
The LLM will process and generate contextual embeddings for search queries and documents.
LangChain will orchestrate the workflow, integrating the LLM with Qdrant
With Qdrant we will store and manage these embeddings efficiently.
(Qdrant enables fast, vector-based searches, ensuring relevant results are retrieved)
Leveraging LangChain’s community integrations, we’ll ensure our search system is robust, scalable, and operates entirely on-premise for enhanced data control.
Project Structure – On premise AI for business
Once you have installed Qdrant and run the finished code, this is what you should have in your project directory:
*I’ve tested with a file called “data.pdf” and a file called “thelaw.pdf”
❯ tree -L 2
.
├── aliases
│ └── data.json
├── app.py
├── collections
│ └── vector_db
├── data.pdf*
├── ingest.py
├── raft_state.json
├── requirements.txt
└── thelaw.pdf*
Install required dependencies
pip install langchain-community langchain_qdrant sentence-transformers qdrant-client huggingface-hub torch pypdf streamlitPython code
- ingest.py
- app.py
We’ll have ingest.py file to ingest the data from the PDF or multiple PDF files that we want to search
app is the file which we will use with a streamlit GUI to query our PDF files (which will be searched with a semantic search).
ingest.py
This Qdrant.from_documents method is responsible for the following actions:
qdrant = Qdrant.from_documents(
texts,
embeddings,
url=url,
prefer_grpc=False,
collection_name="vector_db"
)- Creating the Collection: If the collection with the name
vector_dbdoes not already exist, this method will create it within the Qdrant instance. - Storing Documents: It processes the
textsusing the providedembeddingsmodel and stores the resulting vectors in thevector_dbcollection.
This method handles both the creation of the collection and the insertion of documents into it in one step.
The key part that triggers the collection creation is the combination of the collection_name parameter and the logic within the from_documents method that checks if the collection exists before creating it.
from langchain_community.vectorstores import Qdrant
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
loader = PyPDFLoader("thelaw.pdf")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,
chunk_overlap=50)
texts = text_splitter.split_documents(documents)
# Load the embedding model
model_name = "BAAI/bge-large-en"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
url = "http://localhost:6333"
qdrant = Qdrant.from_documents(
texts,
embeddings,
url=url,
prefer_grpc=False,
collection_name="vector_db"
)
print("vector_db collection successfully created!")app.py
For the GUI we use streamlit as a prototype front end for our app, however, after that, you may wish to build something with JavaScript and HTML
BGE models on the HuggingFace are the best open-source embedding models and above all they allow you to keep your data local!
import streamlit as st
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from qdrant_client import QdrantClient
from langchain_qdrant import QdrantVectorStore
# Define the model and embedding settings
model_name = "BAAI/bge-large-en"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# Set the Qdrant client
url = "http://localhost:6333"
client = QdrantClient(
url=url, prefer_grpc=False
)
# Set up the Qdrant Vector Store - don't just use "Qdrant"
db = QdrantVectorStore(
client=client,
collection_name="vector_db",
embedding=embeddings,
)
# Streamlit UI
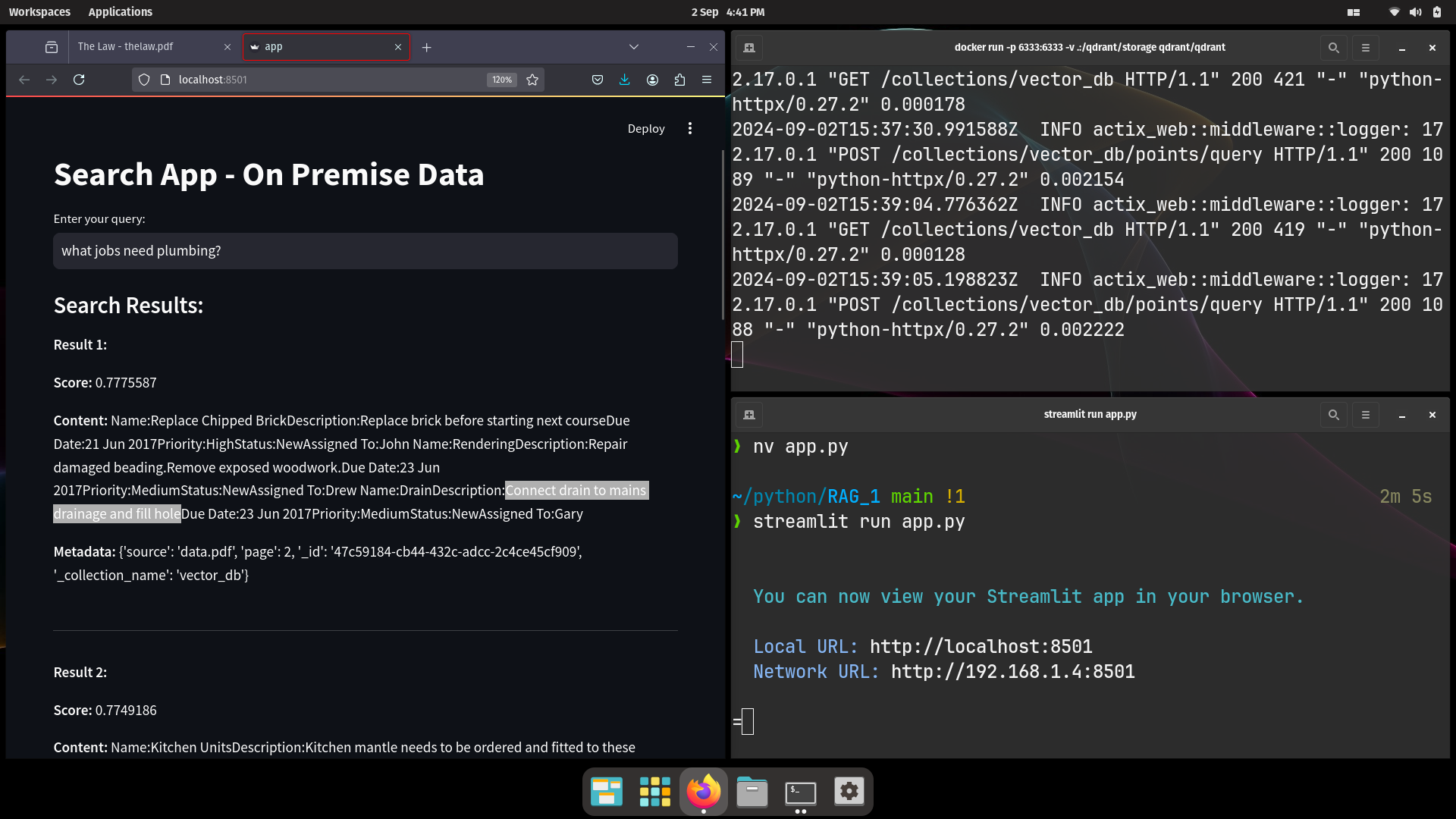
st.title("Search App - On Premise Data")
# Input field for the query text
query = st.text_input("Enter your query:")
if query:
# Perform similarity search - get top 5 results in descending order
docs = db.similarity_search_with_score(query=query, k=5)
# Display the results
st.write("### Search Results:")
for i, (doc, score) in enumerate(docs):
st.write(f"**Result {i + 1}:**")
st.write(f"**Score:** {score}")
st.write(f"**Content:** {doc.page_content}")
st.write(f"**Metadata:** {doc.metadata}")
st.write("-----")
# streamlit run app.py