FastEmbed & Qdrant for Image classification
Introduction
FastEmbed is a lightweight and fast Python library designed for generating high-quality text embeddings.

FastEmbed supports a variety of popular text models and is continuously expanding to include more.
At its core, FastEmbed utilizes the Flag Embedding model from the MTEB leaderboard, offering distinct “query” and “passage” prefixes for input text.
This feature makes it ideal for retrieval embedding generation and seamless integration with tools like Qdrant.
Note it also supports image embedding – eg: Qdrant/clip-ViT-B-32-vision
- https://qdrant.github.io/fastembed
- Get started with Vector Qdrant Database
- View my YouTube Qdrant + AI playlist
- Use the Qdrant client
FastEmbed substantially decreases the time required for embedding generation
Rayyan Shaikh – AI Researcher
Supported models:
You can see which models are currently included here :
https://qdrant.github.io/fastembed/examples/Supported_Models
Why FastEmbed?
Lightweight: FastEmbed is minimalistic with few external dependencies, making it perfect for serverless environments like AWS Lambda. It avoids heavy PyTorch dependencies by leveraging the ONNX Runtime, which requires no GPU and minimal disk space.
Fast: Optimized for speed, FastEmbed uses ONNX Runtime, which outperforms PyTorch in terms of processing speed. It also employs data parallelism to efficiently handle large datasets.
Accurate: FastEmbed delivers superior accuracy compared to models like OpenAI Ada-002. It includes support for multilingual models and continues to grow its model repertoire.
** If you are a Linux user like me, on an older laptop, you may have had issues with Pytorch/Libtorch – I had compile issues when I used Libtorch with Rust also – Fastembed removes all those problems.
This article shows benchmarks for FastEmbed :
Installation
Install FastEmbed effortlessly using pip:
pip install fastembed
# For GPU support
pip install fastembed-gpuQuickstart
from fastembed import TextEmbedding
from typing import List
documents: List[str] = [
"This is built to be faster and lighter than other embedding libraries e.g. Transformers, Sentence-Transformers, etc.",
"fastembed is supported by and maintained by Qdrant.",
]
embedding_model = TextEmbedding()
print("The model BAAI/bge-small-en-v1.5 is ready to use.")
embeddings_generator = embedding_model.embed(documents)
embeddings_list = list(embeddings_generator)
len(embeddings_list[0]) # Vector of 384 dimensionsMake your own
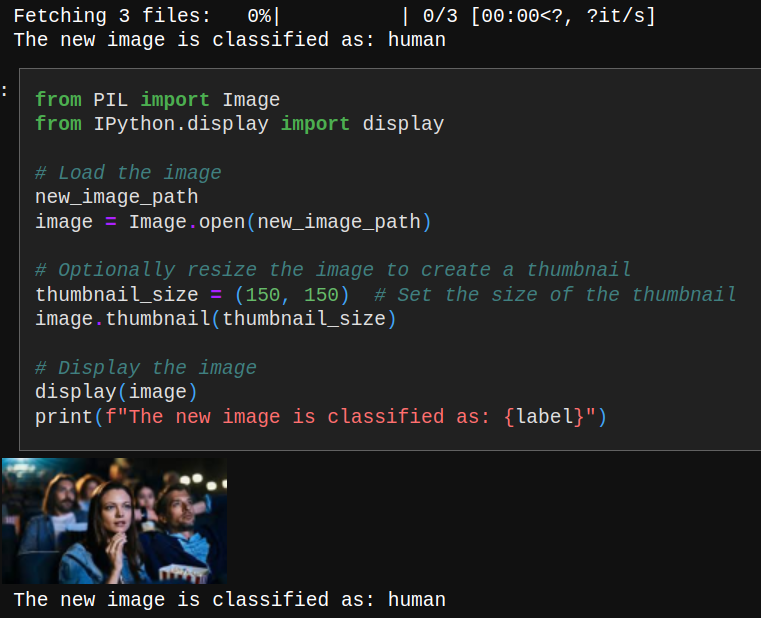
I’ll covered this project in the YouTube video, but here is the successful output where FastEmbed was used along with Qdrant client (and Python). It accurately identifies if the image is of a human or non_human.
Get in touch if you’d like help or have a project – we can use Qdrant, FastEmbed, Python and even run it all on premise which is a bonus – especially in light of so many data breaches and outages nowadays.

