Fastembed for Rig.rs
Use Rig with FastEmbed rather than the OpenAI embeddings builder (cos £)

OpenAI embeddings, using Rig.rs EmbeddingsBuilder
They look like this, but cost money!
let embeddings = EmbeddingsBuilder::new(model)
.document("Some text")?
.document("More text")?
.build()
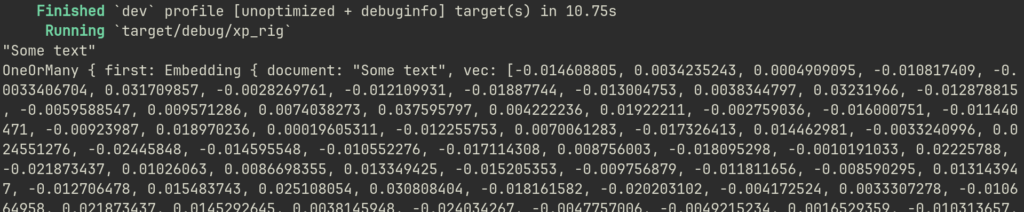
.await?;"Some text"
OneOrMany { first: Embedding { document: "Some text", vec: [-0.014608805, 0.0034235243, 0.0004909095, -0.010817409, -0.0033406704, 0.031709857, -0.0028269761, -0.012109931, -0.01887744, -0.013004753, 0.0038344797, 0.03231966, -0.012878815, -0.0059588547, 0.009571286, 0.0074038273, 0.037595797, 0.004222236, 0.01922211, -0.002759036, -0.016000751, -0.011440471, -0.00923987, 0.018970236, 0.00019605311"More text"
OneOrMany { first: Embedding { document: "More text", vec: [-0.020279586, 0.012406493, -0.002209697, -0.009180805, -0.006441317, 0.030714452, -0.0035241146, -0.009804483, -0.021433055, -0.014351294, -0.009630121, 0.030446203, -0.013881859, -0.013962334, 0.0070146983, -0.0007930096, 0.036991466, 0.001679068, 0.030660802, -0.019984514, -0.009831307, -0.010300742, -0.01841526, -0.00063038396, 0.0037722446, 
Embeddings made using FastEmbed, using same source text

let model = TextEmbedding::try_new(
InitOptions::new(EmbeddingModel::AllMiniLML6V2).with_show_download_progress(true),
)?;
let documents = vec![
"Some text".to_string(),
"More text".to_string()
];
// Generate embeddings with the default batch size, 256
let embeddings = model.embed(documents.clone(), None)?;
// Pair each embedding with the document ID
let document_embeddings: Vec<(String, Embedding)> = documents.into_iter()
.zip(embeddings.into_iter())
.collect();
for (_,x) in document_embeddings{
println!("{:?}", x);
}[-0.01200148, 0.08130821, -0.0100907, 0.011458188, 0.0010404622, 0.061911266, 0.13618088, -0.018939007, 0.12532043, -0.0312798, 0.041772965, 0.056599576, 0.0030611868, 0.001251989, 0.0055824323, 0.031185657, 0.039449655, -0.012576734, -0.08583154, -0.05240699, -0.026867699, 0.10375015, 0.01544964, 0.024841962, -0.05216351, 0.10526828, -0.07732559, 0.04263838, 0.025701094, 0.0012414336, -0.07970881, 0.01741151, 0.12171166, 0.041223485, -0.025700985, 0.01590083, -0.0148574365, 0.030850714, 0.012645943, 0.018317904,Using 1st part of tuple ->
let model = TextEmbedding::try_new(
InitOptions::new(EmbeddingModel::AllMiniLML6V2).with_show_download_progress(true),
)?;
let documents = vec![
"Some text".to_string(),
"More text".to_string()
];
// Generate embeddings with the default batch size, 256
let embeddings = model.embed(documents.clone(), None)?;
// Pair each embedding with the document ID
let document_embeddings: Vec<(String, Embedding)> = documents.into_iter()
.zip(embeddings.into_iter())
.map(|embedding| embedding)
.collect();
for (w,_) in document_embeddings{
println!("{:?}", w);
}
We need to make the Fastembed version work with Rig, but we just have the Vec of f32 from and not all the highlighted blue “stuff” seen from OpenAI below:
The store supports multiple embeddings per document through the OneOrMany enum:
pub enum OneOrMany<T> {
One(T),
Many(Vec<T>),
}

Make some structs to align with Rig requirements
// Define the structures to match Rig.rs expectations
#[derive(Debug)]
struct Embedding {
document: String,
vec: Vec<f32>,
}
#[derive(Debug)]
struct OneOrMany {
first: Embedding,
}use dotenv::dotenv;
use fastembed::{EmbeddingModel, InitOptions, TextEmbedding};
use rig::providers::openai::Client;
use rig::vector_store::in_memory_store::InMemoryVectorStore;
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
dotenv().ok();
let client = Client::from_env();
// Initialize the embedding model
let model = TextEmbedding::try_new(
InitOptions::new(EmbeddingModel::AllMiniLML6V2).with_show_download_progress(true),
)?;
// Input documents
let documents = vec![
"Some text".to_string(),
"More text".to_string(),
];
// Generate embeddings
let embeddings = model.embed(documents.clone(), None)?;
// Transform into Rig.rs-compatible format
let rig_compatible_embeddings: Vec<OneOrMany> = documents.into_iter()
.zip(embeddings.into_iter())
.map(|(document, vec)| {
OneOrMany {
first: Embedding { document, vec },
}
})
.collect();
// Print the Rig.rs-compatible embeddings
for embedding in rig_compatible_embeddings {
println!("{:?}", embedding);
}
Ok(())
}
// Define the structures to match Rig.rs expectations
#[derive(Debug)]
struct Embedding {
document: String,
vec: Vec<f32>,
}
#[derive(Debug)]
struct OneOrMany {
first: Embedding,
}
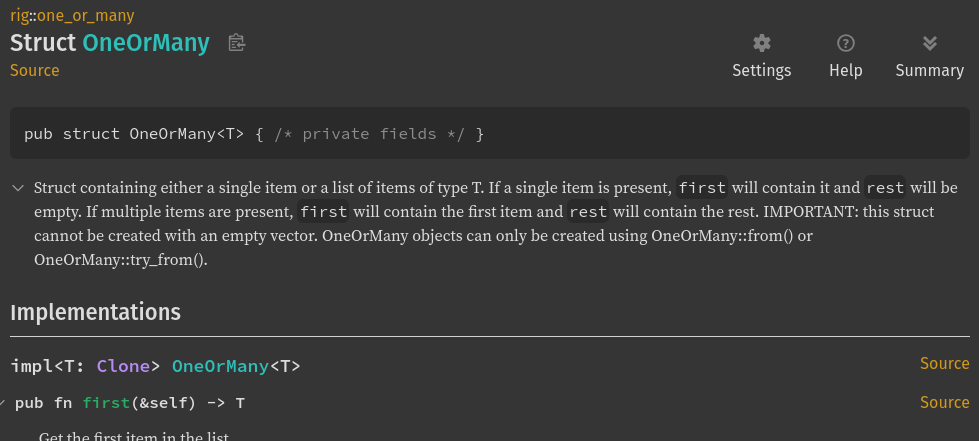
“OneOrMany” – documentation
Progress
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/xp_rig`
[OneOrMany { first: Embedding { document: "Some text", vec: [-0.01200148, 0.08130821, -0.0100907, 0.011458188, 0.0010404622, 0.061911266, 0.13618088, -0.018939007, 0.12532043, -0.0312798, 0.041772965, 0.056599576, 0.0030611868, 0.001251989, 0.0055824323, 0.031185657, 0.039449655, -0.012576734, -0.08583154, -0.05240699, -0.026867699, 0.10375015, 0.01544964, 0.024841962, -0.05216351, 0.10526828, -0.07732559, 0.04263838, 0.025701094, 0.0012414336, -0.07970881, 0.01741151, 0.12171166, 0.041223485, -0.02570098Next : Add the documents
use dotenv::dotenv;
use fastembed::{EmbeddingModel, InitOptions, TextEmbedding};
use rig::providers::openai::Client;
use rig::vector_store::in_memory_store::InMemoryVectorStore;
#[tokio::main]
async fn main() -> Result<(), anyhow::Error> {
dotenv().ok();
let client = Client::from_env();
// Initialize the embedding model
let model = TextEmbedding::try_new(
InitOptions::new(EmbeddingModel::AllMiniLML6V2).with_show_download_progress(true),
)?;
// Input documents
let documents = vec!["Some text".to_string(), "More text".to_string()];
// Generate embeddings
let embeddings = model.embed(documents.clone(), None)?;
// Transform into Rig.rs-compatible format
let rig_compatible_embeddings: Vec<OneOrMany> = documents
.into_iter()
.zip(embeddings.into_iter())
.map(|(document, vec)| OneOrMany {
first: Embedding { document, vec },
})
.collect();
// Example usage: printing or returning
for entry in &rig_compatible_embeddings {
println!(
"Document: {}, Embedding: {:?}",
entry.first.document, entry.first.vec
);
}
Ok(())
}
// Define the structures to match Rig.rs expectations
#[derive(Debug)]
struct Embedding {
document: String,
vec: Vec<f32>,
}
#[derive(Debug)]
struct OneOrMany {
first: Embedding,
}

Ok…so now I have come full circle and just using qdrant + fastembed to do the embeddings!
Next : make a tool, so that rig can query the vector database

